Think about any production network. What defines the exact intended configuration of each device in a production network? Is it the running-config as it exists right now or the startup-config before any recent changes were made or the startup-config from last month? Could one engineer change the device configuration so that it drifts away from that ideal, with the rest of the staff not knowing? What process, if any, might discover the configuration drift? And even with changes agreed upon by all, how do you know who changed the configuration, when, and specifically what changed?
Traditionally, we look how to configure one device using the configure terminal command to reach configuration mode, which changes the running-config file, and how to save that running-config file to the startup-config file. That manual process provides no means to answer any of the legitimate questions posed in the first paragraph; however, for many enterprises, those questions (and others) need answers, both consistent and accurate. Not every company reaches the size to want to do something more with configuration management. Companies with one network engineer might do well enough managing device configurations, especially if the network device configurations do not change often. However, as a company moves to multiple network engineers and grows the numbers of devices and types of devices, with higher rates of configuration change, manual configuration management has problems.
Ansible, Puppet, and Chef Basics
Ansible, Puppet, and Chef are software packages. You can purchase each tool, with variations on which package. However, they all also have different free options that allow you to download and learn about the tools, although you might need to run a Linux guest because some of the tools do not run in a Windows OS. As for the names, most people use the words Ansible, Puppet, and Chef to refer to the companies as well as their primary configuration management products. All three emerged as part of the transition from hardware-based servers to virtualized servers, which greatly increased the number of servers and created the need for software automation to create, configure, and remove VMs . All three produce one or more configuration management software products that have become synonymous with their companies in many ways.
Ansible
To use Ansible (www.ansible.com), you need to install Ansible on some computer: Mac, Linux, or a Linux VM on a Windows host. You can use the free open-source version or use the paid Ansible Tower server version. Once it is installed, you create several text files, such as the following:
- Playbooks: These files provide actions and logic about what Ansible should do.
- Inventory: These files provide device hostnames along with information about each device, like device roles, so Ansible can perform functions for subsets of the inventory
- Templates: Using Jinja2 language, the templates represent a device’s configuration but with variables.
- Variables: Using YAML, a file can list variables that Ansible will substitute into templates.
As far as how Ansible works for managing network devices, it uses an agentless architecture. That means Ansible does not rely on any code (agent) running on the network device. Instead, Ansible relies on features typical in network devices, namely SSH and/or NETCONF, to make changes and extract information. When using SSH, the Ansible control node actually makes changes to the device like any other SSH user would do, but doing the work with Ansible code, rather than with a human.
Ansible can be described as using a push model rather than a pull model (like Puppet and Chef). After installing Ansible, an engineer needs to create and edit all the various Ansible files, including an Ansible playbook. Then the engineer runs the playbook, which tells Ansible to perform the steps. Those steps can include configuring one or more devices per the various files (step 3), with the control node seen as pushing the configuration to the device.
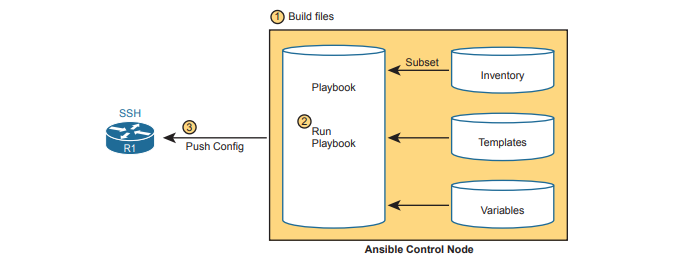
As with all the tools, Ansible can do both configuration provisioning (configuring devices after changes are made in the files) and configuration monitoring (checking to find out whether the device config matches the ideal configuration on the control node). However, Ansible’s architecture more naturally fits with configuration provisioning, as seen in the figure. To do configuration monitoring, Ansible uses logic modules that detect and list configuration differences, after which the playbook defines what action to take (reconfigure or notify).
Puppet
To use Puppet (www.puppet.com), like Ansible, begin by installing Puppet on a Linux host. You can install it on your own Linux host, but for production purposes, you will normally install it on a Linux server called a Puppet master. As with Ansible, you can use a free opensource version with paid versions available. You can get started learning Puppet without a separate server for learning and testing. Once installed, Puppet also uses several important text files with different components, such as the following:
- Manifest: This is a human-readable text file on the Puppet master, using a language defined by Puppet, used to define the desired configuration state of a device.
- Resource, Class, Module: These terms refer to components of the manifest, with the largest component (module) being composed of smaller classes, which are in turn composed of resources.
- Templates: Using a Puppet domain-specific language, these files allow Puppet to generate manifests (and modules, classes, and resources) by substituting variables into the template.
One way to think about the differences between Ansible’s versus Puppet’s approach is that Ansible’s playbooks use an imperative language, whereas Puppet uses a declarative language. For instance, with Ansible, the playbook will list tasks and choices based on those results, like “Configure all branch routers in these locations, and if errors occur for any device, do these extra tasks for that device.” Puppet manifests instead declare the end state that a device should have: “This branch router should have the configuration in this file by the end of the process.” The manifest, built by the engineer, defines the end state, and Puppet has the job to cause the device to have that configuration, without being told the specific set of steps to take.
Puppet typically use an agent-based architecture for network device support. Some network devices enable Puppet support via an on-device agent—think of it as another feature configurable on the device. However, not every Cisco OS supports Puppet agents, so Puppet solves that problem using a proxy agent running on some external host (called agentless operation). The external agent then uses SSH to communicate with the network device, as shown in figure.
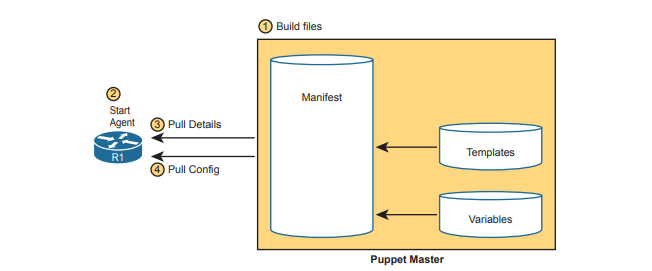
Armed with a manifest that declares something like “This device should have this configuration state,” Puppet uses a pull model to make that configuration appear in the device, as shown in figure below. Once installed, these steps occur:
Chef
Chef (www.chef.io), as with Ansible and Puppet, exists as software packages you install and run. Chef (the company) offers several products, with Chef Automate being the product that most people refer to simply as Chef. As with Puppet, in production you probably run Chef as a server (called server-client mode), with multiple Chef workstations used by the engineering staff to build Chef files that are stored on the Chef server. However, you can also run Chef in standalone mode (called Chef Zero), which is helpful when you’re just getting started and learning in the lab. Once Chef is installed, you create several text files with different components, like the following:
- Resource: The configuration objects whose state is managed by Chef; for instance, a set of configuration commands for a network device—analogous to the ingredients in a recipe in a cookbook
- Recipe: The Chef logic applied to resources to determine when, how, and whether to act against the resources—analogous to a recipe in a cookbook
- Cookbooks: A set of recipes about the same kinds of work, grouped together for easier management and sharing
- Runlist: An ordered list of recipes that should be run against a given device
Chef uses an architecture similar to Puppet. For network devices, each managed device (called a Chef node or Chef client) runs an agent. The agent performs configuration monitoring in that the client pulls recipes and resources from the Chef server and then adjusts its configuration to stay in sync with the details in those recipes and runlists. Note however that Chef requires on-device Chef client code, and many Cisco devices do not support a Chef client, so you will likely see more use of Ansible and Puppet for Cisco device configuration management.



